Workers & Jobs
In Airbyte, all interactions with connectors are run as jobs performed by a Worker. Each job has a corresponding worker:
- Spec worker: retrieves the specification of a connector (the inputs needed to run this connector)
- Check connection worker: verifies that the inputs to a connector are valid and can be used to run a sync
- Discovery worker: retrieves the schema of the source underlying a connector
- Sync worker, used to sync data between a source and destination
Thus, there are generally 4 types of workers.
Note: Workers here refers to Airbyte workers. Temporal, which Airbyte uses under the hood for scheduling, has its own worker concept. This distinction is important.
Sync Jobs
At a high level, a sync job is an individual invocation of the Airbyte pipeline to synchronize data from a source to a destination data store.
Sync Job State Machine
Sync jobs have the following state machine.
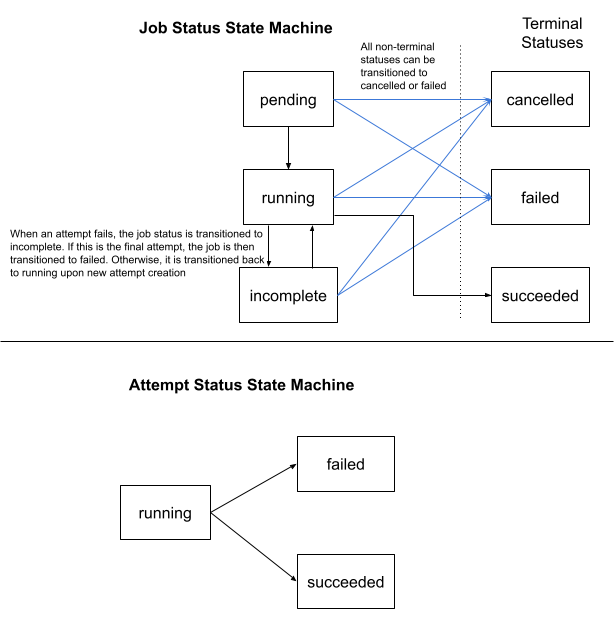
Attempts and Retries
In the event of a failure, the Airbyte platform will retry the pipeline. Each of these sub-invocations of a job is called an attempt.
Retry Rules
Based on the outcome of previous attempts, the number of permitted attempts per job changes. By default, Airbyte is configured to allow the following:
- 5 subsequent attempts where no data was synchronized
- 10 total attempts where no data was synchronized
- 10 total attempts where some data was synchronized
For oss users, these values are configurable. See Configuring Airbyte for more details.
Retry Backoff
After an attempt where no data was synchronized, we implement a short backoff period before starting a new attempt. This will increase with each successive complete failure—a partially successful attempt will reset this value.
By default, Airbyte is configured to backoff with the following values:
- 10 seconds after the first complete failure
- 30 seconds after the second
- 90 seconds after the third
- 4 minutes and 30 seconds after the fourth
For oss users, these values are configurable. See Configuring Airbyte for more details.
The duration of expected backoff between attempts can be viewed in the logs accessible from the job history UI.
Retry examples
To help illustrate what is possible, below are a couple examples of how the retry rules may play out under more elaborate circumstances.
| Job #1 | |
|---|---|
| Attempt Number | Synced data? |
| 1 | No |
| 10 second backoff | |
| 2 | No |
| 30 second backoff | |
| 3 | Yes |
| 4 | Yes |
| 5 | Yes |
| 6 | No |
| 10 second backoff | |
| 7 | Yes |
| Job succeeds — all data synced | |
| Job #2 | |
|---|---|
| Attempt Number | Synced data? |
| 1 | Yes |
| 2 | Yes |
| 3 | Yes |
| 4 | Yes |
| 5 | Yes |
| 6 | Yes |
| 7 | No |
| 10 second backoff | |
| 8 | No |
| 30 second backoff | |
| 9 | No |
| 90 second backoff | |
| 10 | No |
| 4 minute 30 second backoff | |
| 11 | No |
| Job Fails — successive failure limit reached | |
Worker Responsibilities
The worker has the following responsibilities.
- Handle the process lifecycle for job-related processes. This includes starting, monitoring and shutting down processes.
- Facilitate message passing to or from various processes, if required. (more on this below).
- Handle job-relation operational work such as:
- Basic schema validation.
- Returning job output, including any error messages. (See Airbyte Specification to understand the output of each worker type.)
- Telemetry work e.g. tracking the number and size of records within a sync.
Conceptually, workers contain the complexity of all non-connector-related job operations. This lets each connector be as simple as possible.
Worker Types
There are 2 flavors of workers:
Synchronous Job Worker - Workers that interact with a single connector (e.g. spec, check, discover).
The worker extracts data from the connector and reports it to the scheduler. It does this by listening to the connector's STDOUT. These jobs are synchronous as they are part of the configuration process and need to be immediately run to provide a good user experience. These are also all lightweight operations.
Asynchronous Job Worker - Workers that interact with 2 connectors (e.g. sync, reset)
The worker passes data (via record messages) from the source to the destination. It does this by listening on STDOUT of the source and writing to STDIN on the destination. These jobs are asynchronous as they are often long-running resource-intensive processes. They are decoupled from the rest of the platform to simplify development and operation.
For more information on the schema of the messages that are passed, refer to Airbyte Specification.
Worker-Job Architecture
This section will depict the worker-job architecture as discussed above. Only the 2-connector version is shown. The single connector version is the same with one side removed.
The source process should automatically exit after passing all of its messages. Similarly, the destination process shutdowns after receiving all records. Each process is given a shutdown grace period. The worker forces shutdown if this is exceeded.
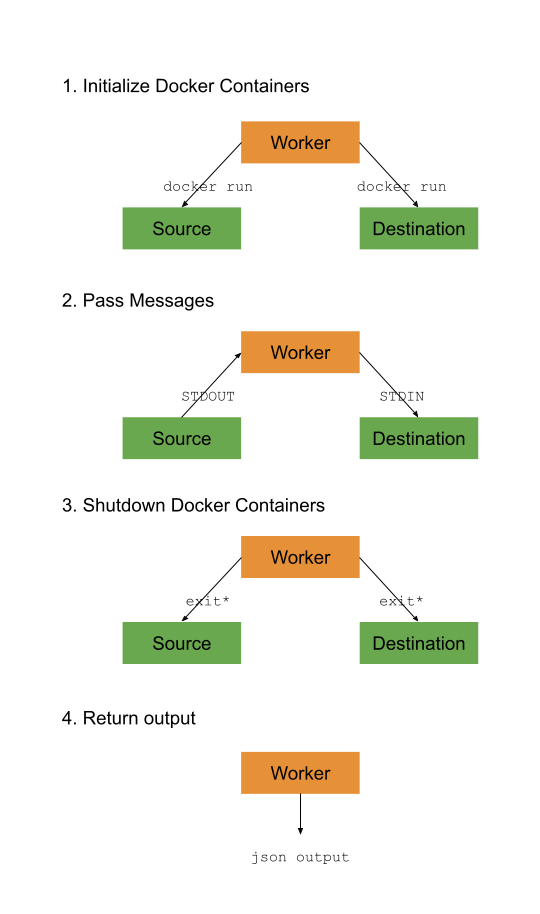
See the architecture overview for more information about workers.
Deployment Types
Up to now, the term 'processes' has been used loosely. This section will describe this in more detail.
Airbyte offers two deployment types. The underlying process implementations differ accordingly.
- The Docker deployment - Each process is a local process backed by a Docker container. As all processes are local, process communication is per standard unix pipes.
- The Kubernetes deployment - Each process is a backed by a Kubernetes pod. As Kubernetes does not make process-locality guarantees, Airbyte has implemented mechanisms to hide the remote process execution. See this blogpost for more details.
Decoupling Worker and Job Processes
Workers being responsible for all non-connector-related job operations means multiple jobs are operationally dependent on a single worker process.
There are two downsides to this:
- Any issues to the parent worker process affects all job processes launched by the worker.
- Unnecessary complexity of vertically scaling the worker process to deal with IO and processing requirements from multiple jobs.
This gives us a potentially brittle system component that can be operationally tricky to manage. For example, since redeploying Airbyte terminates all worker processes, all running jobs are also terminated.
The Container Orchestrator was introduced to solve this.
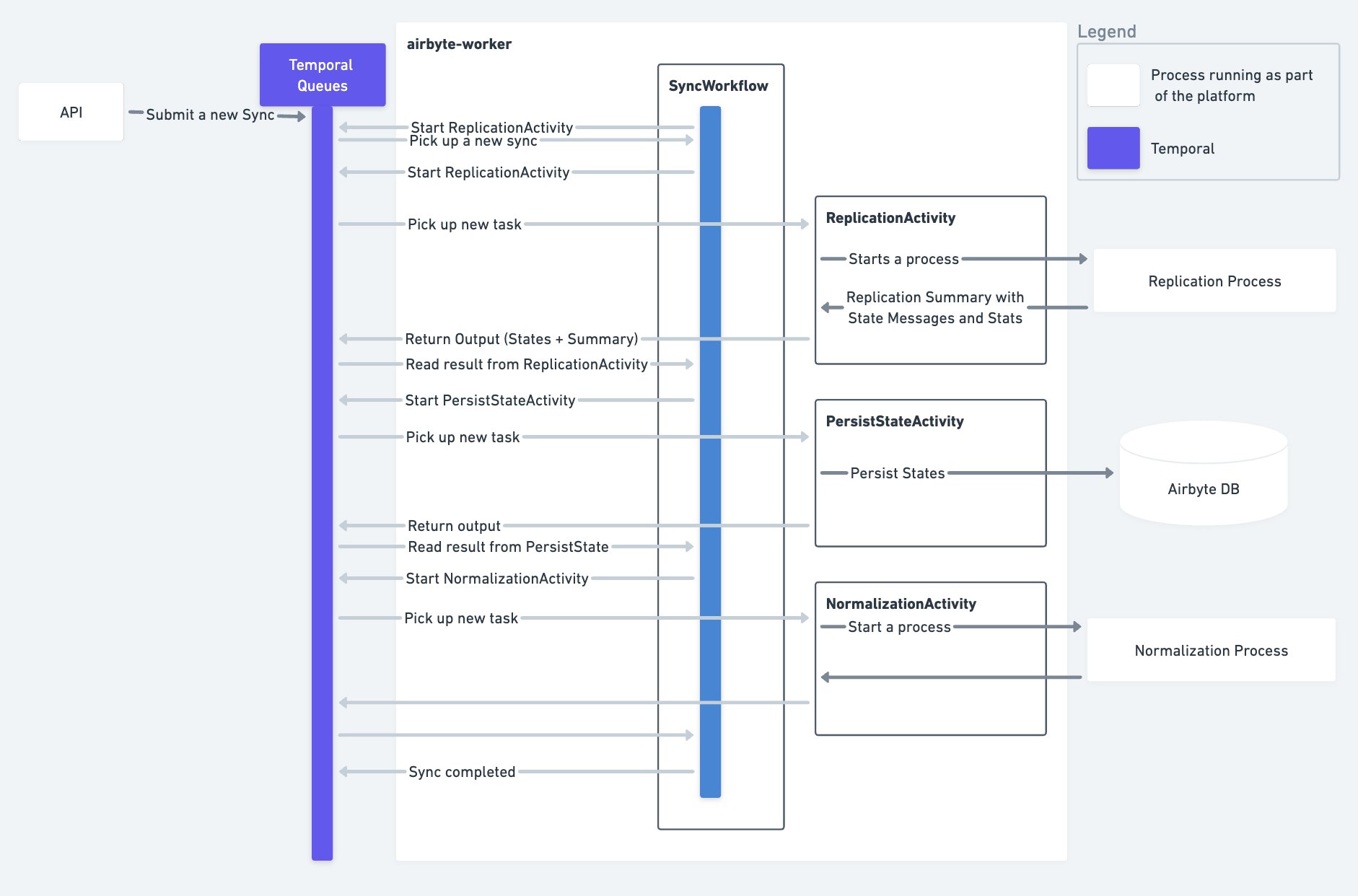
Container Orchestrator
When enabled, workers launch the Container Orchestrator process.
The worker process delegates the above listed responsibilities to the orchestrator process.
This decoupling introduces a new need for workers to track the orchestrator's, and the job's, state. This is done via a shared Cloud Storage store.
Brief description of how this works,
- Workers constantly poll the Cloud Storage location for job state.
- As an Orchestrator process executes, it writes status marker files to the Cloud Storage location i.e.
NOT_STARTED,INITIALIZING,RUNNING,SUCCESS,FAILURE. - If the Orchestrator process runs into issues at any point, it writes a
FAILURE. - If the Orchestrator process succeeds, it writes a job summary as part of the
SUCCESSmarker file.
The Cloud Storage store is treated as the source-of-truth of execution state.
The Container Orchestrator is only available for Airbyte Kubernetes today and automatically enabled when running the Airbyte Helm Charts deploys.
Users running Airbyte Docker should be aware of the above pitfalls.
Configuring Jobs & Workers
Details on configuring jobs & workers can be found here.
Worker Parallization
Airbyte exposes the following environment variable to change the maximum number of each type of worker allowed to run in parallel. Tweaking these values might help you run more jobs in parallel and increase the workload of your Airbyte instance:
MAX_SPEC_WORKERS: Maximum number of Spec workers allowed to run in parallel.MAX_CHECK_WORKERS: Maximum number of Check connection workers allowed to run in parallel.MAX_DISCOVERY_WORKERS: Maximum number of Discovery workers allowed to run in parallel.MAX_SYNC_WORKERS: Maximum number of Sync workers allowed to run in parallel.
The current default value for these environment variables is currently set to 5.